A couple of weeks ago, I had a problem. It appeared that my refrigerator was failing to keep the cool food section, well, cool. Freezer was fine, but the thermometer I had in the cool food section was showing between 50-60 degrees F, which is far too warm.
This wasn’t the first time this had happened, and on previous occasions, the issue was ice buildup in the freezer that blocked the channel allowing cold air to move from the freezer to the cool food section. So I largely skipped over diagnosis, and jumped straight into trying to fix the issue by running a couple of defrost cycles. I also did a cleaning of the coils under the fridge which, thanks to our dog, were pretty nasty, in case that might be contributing to the problem.
I’ll spare my readers a photo, as I would not want to cause any nightmares. Suffice it to say, if you have pets, check and clean your coils regularly.
Savvy troubleshooters among the readers may have already figured out where I’m going with this, but it turned out that the fridge was actually fine. I didn’t hurt anything by running the defrost, and I’m sure clearing the coils of dog fur made for more efficient cooling, but the central problem in this case was a sensor that was misreporting the temperature. I figured that out by moving a separate smart temperature sensor into the cool food section and monitoring it, which told me that the temperature was, in fact, just fine.
Check Your Assumptions
My problem was that instead of troubleshooting from a clean slate, I brought in a set of assumptions based on prior experience. Those assumptions are a shortcut, and in many cases that shortcut can lead to the right conclusion. But when it doesn’t, it can cost us in time or money in pursuing the wrong problem.
This can happen in the software world as well. Many developers will, over their career, work with multiple programming languages, platforms and paradigms, and the assumptions that work for one platform may not readily apply to others. So it’s really important to make sure that you’re aware of any assumptions you’re bringing to the table when you are working with a new platform (or even switching between platforms that you’re familiar with).
Know Your Defaults
One of the places this came up for me recently is during some code reviews that I’ve been participating in going over several applications built on the OutSystems low-code platform. OutSystems, like many low-code platforms, is designed to simplify and accelerate the process of creating, updating, and maintaining applications by the use of visual tools and paradigms for most of the standard programming structures, including functions and exception handling.
In OutSystems, what would typically be called a function or subroutine in a language such as C# or Java is called an Action, and is modeled as a visual flow from a start to an end node, with other nodes representing other Actions that are called, logical nodes like If, Switch, etc. Alongside the main flow, developers can also define one or more exception handling flows.
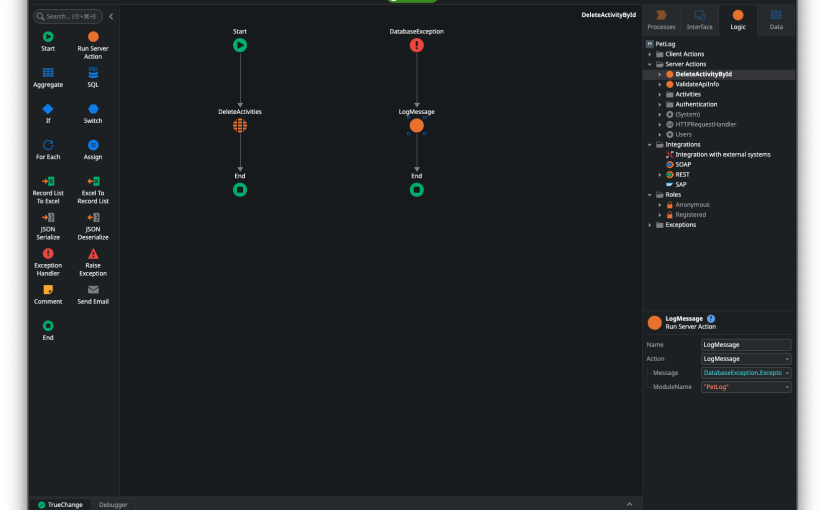
In our code reviews, Justin James, who was leading the code review, noted several instances where the exception handler logic was calling a system Action called LogMessage to log the exception information. Sounds pretty normal, right? If you’re coming from a platform like .NET, this may seem perfectly fine, because in a high-code world, you do typically have to define your logging explicitly.
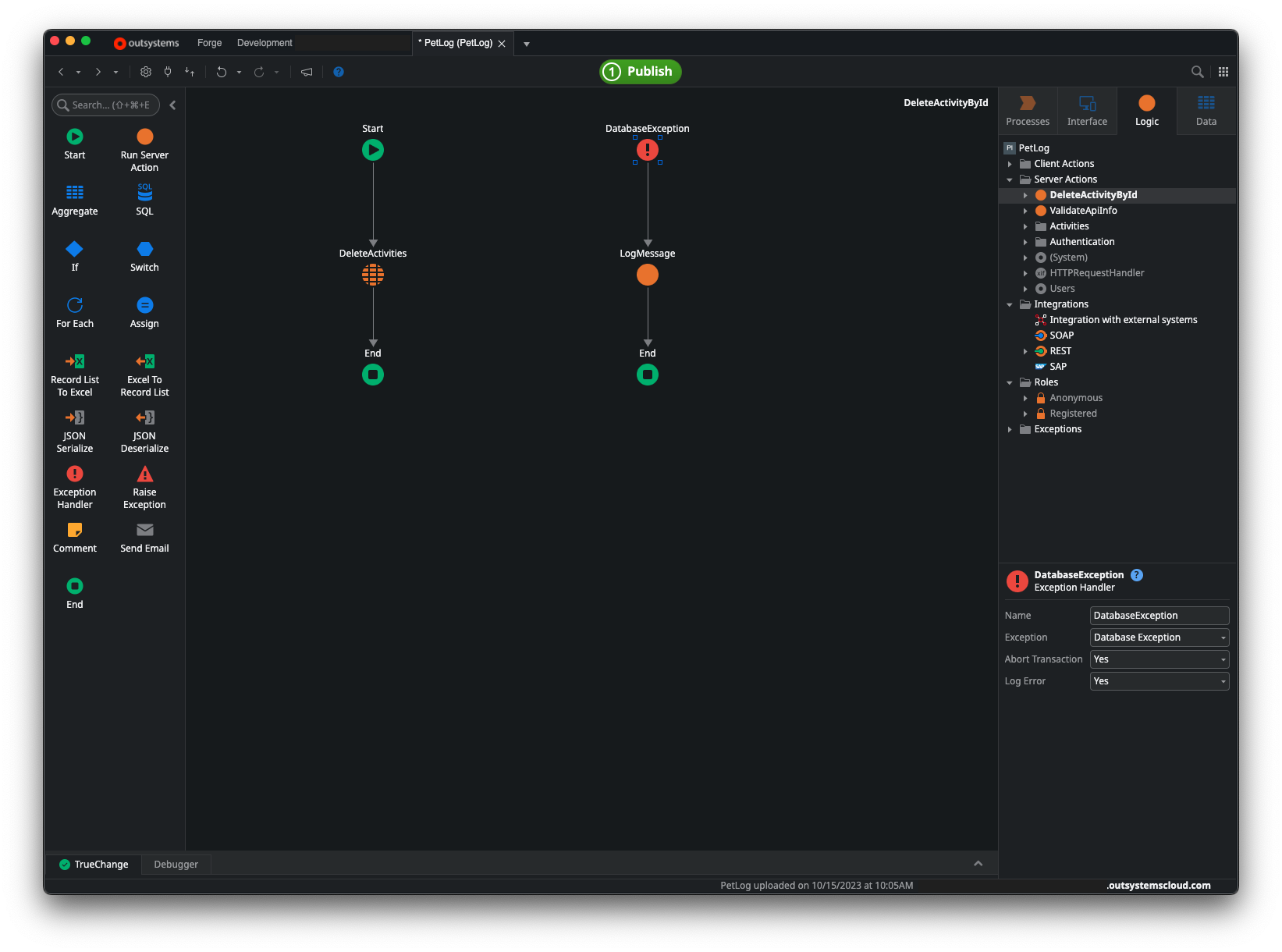
In OutSystems, however, the beginning node of an exception handler flow provides options for automatically logging the exception information, and this option is enabled by default, as shown above. So by logging the exception information explicitly in the flow, the developers were inadvertently double-logging the same information.
As Justin observed, there may well be occasions where you want to explicitly call LogMessage in order to log information above and beyond the standard exception information, but just logging the error message is redundant and provides no additional information to help troubleshoot the error. The developers were trying to do the right thing, but because they did not know the default behavior of the exception flow was to log the error, they were duplicating effort unknowingly. This is illustrated in the screenshot below:
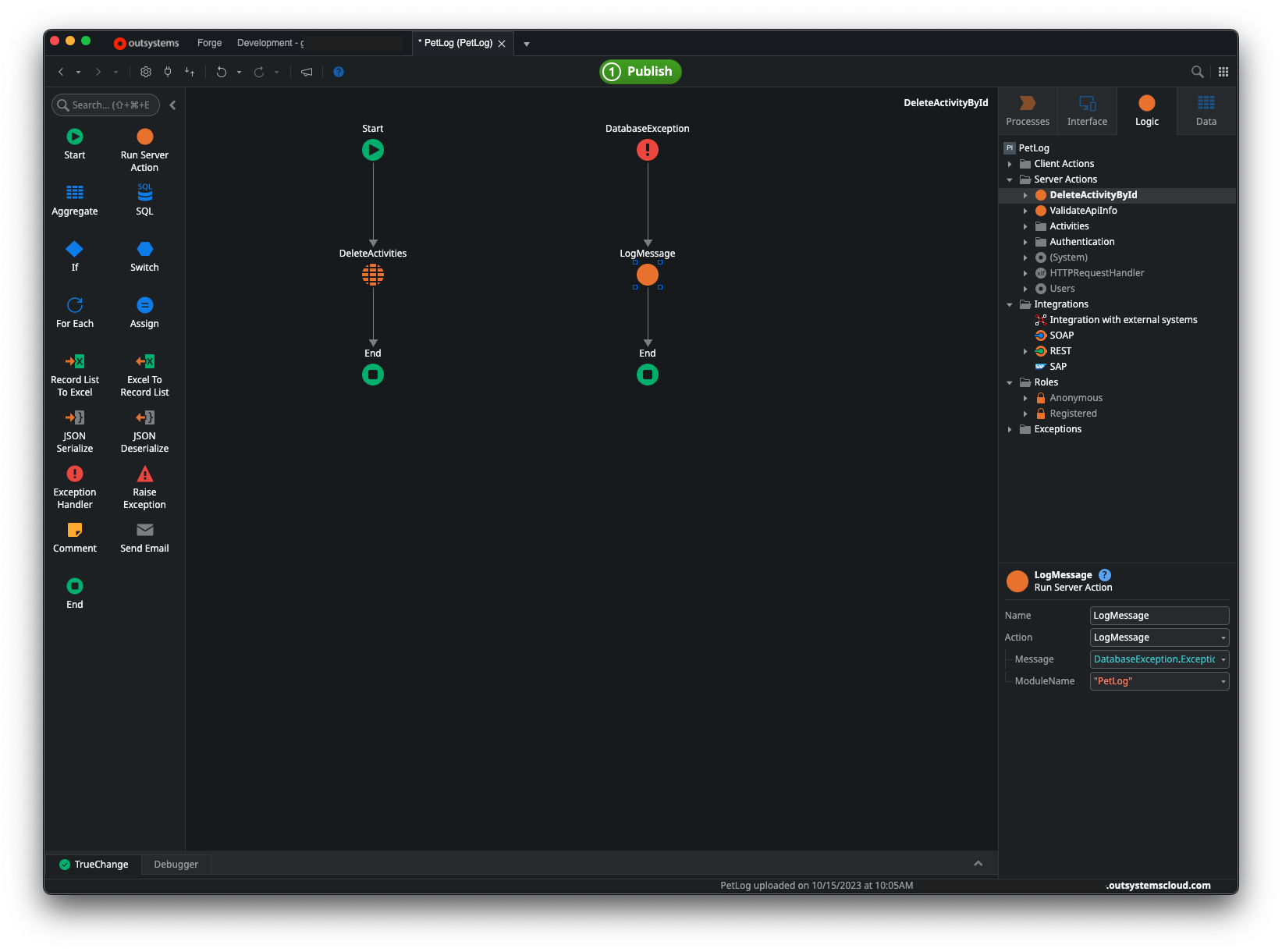
For what it’s worth, I’ve been working with OutSystems for years, and I didn’t know that was the default behavior, so I learned something new as part of this process as well.
For those doing a lot of work on the client side, note that exceptions in Client Actions also log error information by default, though it should be noted that the specific type of exception above, the DatabaseException, does have a major difference between the Client Action and Server Action implementations in that the latter includes an option to abort the implicit transaction that is part of the default behavior for Server Actions when working with the platform database. The DatabaseException on a Client Action does not provide this option.
Challenge Yourself
So how do we avoid falling into the trap of working from assumptions that may not apply? One way is to challenge ourselves to spend time going back to basics. Whether that’s troubleshooting a problematic appliance as if it was the very first time we’re looking at it, or engaging in code reviews (formally or informally) that may help reveal things we weren’t aware of in our platform of choice, taking a step back from the day-to-day to get back into learning mode can reduce the risk of wasted time and money based on incorrect assumptions.
Do you have any favorite stories of gotchas based on incorrect assumptions or misunderstood defaults? I’d love to hear them…drop a comment below!
Comments
Comment by Joe Marini on 2024-03-18 18:16:42 +0000
That seems to me like an instance where the tool itself should catch that condition and issue a warning in the IDE.
Comment by G. Andrew Duthie on 2024-03-18 18:22:10 +0000
Thanks for the comment, Joe!
You could make a case for that, sure.
But as I noted in the post, there’s nothing inherently wrong with logging inside an exception handler flow…as long as you’re logging things that add value for troubleshooting, so in order to have Service Studio flag the additional logging as a warning, you’d either have a lot of potential false positives (bad, since that tends to lead developers to ignore warnings through fatigue), or you’d have to have the IDE analyze what’s being logged to know if it’s redundant. I’m open to being convinced that the latter would be helpful, but I’m not sure how high I’d place that on my priority scale in terms of improvements I’d want addressed soonest.
Comment by Joe Marini on 2024-03-19 15:15:19 +0000
VS Code does a great job of this. It flags things at different levels to indicate errors vs. potential improvements. It’s not necessary to treat it as an error. In this day and age I expect a modern IDE to help developers actively improve their code.
Comment by G. Andrew Duthie on 2024-03-19 15:40:22 +0000
I definitely agree that VS Code is a great tool, and the more an IDE can do to help the developer the better. In fairness to OutSystems, Service Studio does a lot of this with TrueChange monitoring.
Thanks again for sharing your perspective.