Tags
1 page
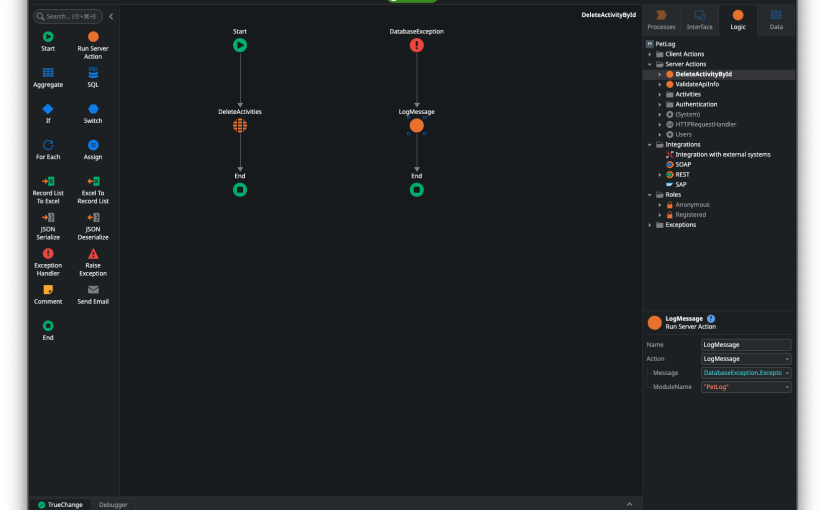
Exception Handling
Check Your Assumptions, Know Your Defaults